Benutzer-Werkzeuge
Seitenleiste
Inhaltsverzeichnis
Einen Kassenbon lesen
Inhaltsverzeichnis
- Projektbeschreibung
- Projektplanung
- Symbol-Finder
- Machine Learning
- Ausblick
Projekbeschreibung
Idee
Der Gedanke war, dass es echt praktisch wäre, wenn man einfach ein Bild von einem Kassenzettel machen könnte und das Programm automatisch den Text erkennen kann. So könnte man die Daten elektronisch verarbeiten, ohne sie erst mühsam vom Bon abzuschreiben.
Planung
Wir haben uns entschieden, das Projekt in zwei Bereiche zu unterteilen:
1) Symbole finden und ausschneiden. (Tessa Ibs, Jan Philipps)
- Anfang des Textes finden.
- Obere linke Ecke des ersten Symbols finden.
- Untere rechte Ecke des ersten Symbols finden.
- Nächstes Symbol finden.
- Wieder Ecken finden usw. bis die Zeile zu Ende ist.
- Anfang der nächsten Zeile finden und vorherige Schritte wiederholen.
2) Die Ausgeschnittenen Symbole erkennen.
- Bilder von Fonts erstellen
- Bilder zurechtschneiden
- Bilder in richtigem Ordner abspeichern
- Neuronales Netzwerk erstellen und trainieren
- Bilder von Neuronales Netzwerk klassifizieren lassen
- gefundene Buchstaben in eine String ausgeben
Symbol-Finder
Der Symbol-Finder ist während der „Konstruktion“ von dem anfangs geplanten Aufbau abgewichen. Das war aber eigentlich von Anfang an klar. Anstatt den ersten Buchstaben zu finden, wird der Bon nun Zeile für Zeile durchsucht. Dadurch können nun die die Ober- und Unterkante der Zeile als Kanten des ausgeschnittenen Symbols benutzt werden. So werden auch die Punkte von Umlauten usw. in das Bild übernommen, obwohl sie nicht mit dem Rest des Zeichens verbunden sind. Ein weiterer Vorteil ist, dass man nun Informationen zur Position innerhalb der Zeile hat. Damit kann man zum Beispiel Bindestriche von Unterstrichen unterscheiden.
"Main"-Methode
Name im Code: SymbolScanner. Diese Methode wird vom Primärteil des Programms (neuronales Netz usw.) aufgerufen. Sie nutzt verschiedene Hilfsmethoden um das Bild Zeile für Zeile zu durchsuchen und möglichst alle Symbole auf dem Kassenbon zu finden und als kleine Bilder zu speichern.
Die gefundenen Symbole werden in Format Zeile_xKoordinate_yKoordinate.png gespeichert.
def SymbolScanner(): img = cv2.imread('img1.png') #Oeffnet das Bild img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #Konvertiert das Bild zu schwarz-weiss/Graustufen h,b=img.shape #h ist die Hoehe des Bildes, b ist die Breite des Bildes threshold=Plotton(img,h,b) #Ruft Plotton auf, um Grenzwert zu erhalten EndPage=False #Erstellt boolean-Variable EndPage und setzt sie auf False zeichen=[] #Erstellt eine (noch) leere Liste CurrentLine=0 #Diese Variable speichert spaeter, in welcher Zeile sich das Programm gerade befindet xMax=0 #Linke Grenze fuer das Programm, damit nichts doppelt gescannt wird. yMax=0 #Obere Grenze fuer das Programm, damit nichts doppelt gescannt wird. #Zeit1=time() #Startet Zeitmessung. Auskommentiert weil meist sinnlos, aber manchmal doch ganz nett zu wissen. while EndPage==False: #Diese Schleife wird ausgefuehrt, solange die Seite nicht bis zum Ende ueberprueft wurde xMax=0 #Setzt die linke Grenze nach jeder Zeile wieder auf 0 zO,zU=ZeilenFindo(h,b,yMax,threshold,img) #Ruft ZeilenFindo auf, um Zeilenober- und Untergrenze zu bestimmen yMax=zU #Setzt Obergrenze fuer naechsten Aufruf von ZeilenFindo, damit nur der Bereich unterhalb der vorherigen Zeile durchsucht wird CurrentLine=CurrentLine+1 #Merkt sich die aktuelle Zeile xS, yS=Skannomaton(zU,b,xMax,zO,threshold,img) #Ruft Skannomatin auf, um x- und y-Koordinate des ersten Symbols zu finden ySH=Korrektoid(xS,yS,threshold,img) #Verbessert den gefundenen y-Wert, um Fehler zu vermeiden if (xS==0) and (yS==0): #Ueberprueft, ob Skannomaton das Seitenende erreicht hat und sorgt dafür, dass das Bild nicht weiter durchsucht wird. EndPage=True EndLine=False #Speichert, dass der Alorithmus sich nicht am Zeilenende befindet while (EndLine==False) and (EndPage==False): #Diese Schleife durchsucht die Zeile nach Buchstaben (ein Durchlauf pro Zeichen) und speichert diese xE,yE=Findomat_UR(xS,yS,ySH,threshold,img) #Ruft Findomat_UR auf, um untere rechte Ecke des Zeichens zu finden xT,yT=Korrektomat(xE,yE,threshold,img) #Korrektomat veraendert die gefundenen Koordinaten um Fehler zu verhindern xA,yA=Findomat_OL(xT,yT,threshold,img) #Ruft Findomat_OL auf, um obere linke Ecke des Zeichens zu finden zeichen.append(img[yA:yE,xA:xE]) #Speichert den Ausschnitt in einer Liste path=os.getcwd() #Holt sich den Programmpfad pInfo=str(CurrentLine)+"_"+str(xA)+"_"+str(yA)+".png" #Baut den Dateinamen zusammen (Zeile_xKoordinate_yKoordinate.png) pPath=os.path.join(os.getcwd(),'SymbolGen') #Baut den Speicher-Pfad zusammen try: os.mkdir(pPath) #Erstellt Speicherverzeichnis falls noch nicht vorhanden except: pass pPath=os.path.join(pPath, pInfo) #Klebt Speicherpfad und Dateinamen zusammen imsave( pPath, zeichen[-1]) #Speichert neustes Bild in der Liste unter dem Pfad von eben ab xS,yS=Skannomaton(zU,b,xE,zO,threshold,img) #Nutzt Skannomaton,um nächstes Zeichn zu finden ySH=Korrektoid(xS,yS,threshold,img) #Verbessert den gefundenen y-Wert, um Fehler zu vermeiden if (xS==0) and (yS==0): #Schaut nach, ob Skannomaton am Zeilendende angekommen ist und sorgt dafür, dass die Zeile nicht weiter durchsucht wird. EndLine=True #Zeit2=time() #Beendet Zeitmessung. Auskommentiert weil meist sinnlos, aber manchmal doch ganz nett zu wissen. #print "SymbolScanner-Time=", (Zeit2-Zeit1) #Gibt an, wie lange die ganze Suche gedauert hat. Auskommentiert weil meist sinnlos, aber manchmal doch ganz nett zu wissen.
Grenzwert-Berechner
Name im Code: Plotton. Diese Methode sollte eigentlich den optimalen Grenzwert berechnen, ab dem ein Pixel als Teil eines Zeichens erkannt wird. Da aber je nach Art, Beleuchtung und Zustand des Kassenbons dieser Wert und die quantitative Verteilung der Helligkeitswerte stark variiert, ist es uns nicht gelungen einen Algorithmus zu finden, der einen sinnvollen Wert hervorbringt. Deshalb erstellt diese Methode nun ein Histogram, in dem der Anteil jedes Helligkeitswertes in Prozent dargestellt wird. Das Histogram wird ausgegeben und soll dem Nutzer helfen, selbst einen sinvollen Grenzwert zu bestimmen, der manuell eingegeben werden muss.
def Plotton(img,h,b): #img=BildMatrix; h=Bildhoehe in Pixeln; b=BildBreite in Pixeln; pixelCounter=[0]*256 #Erstellt Liste mit 256 Slots, fuer jeden Farbwert einen nOFpixels=float(h*b) #Anzahl der Pixel im Bild for y in range(h): #Diese Schleife Zaehlt die Haeufigkeit der Helligkeitswerte for x in range(b): pixelCounter[img[y,x]]=pixelCounter[img[y,x]]+1 for n in range(len(pixelCounter)): #Diese Schleife Teilt jedes Listenelement durch die Anzahl der Pixel, (Absolute zur relativen Haeufigkeit) pixelCounter[n]=100.*(pixelCounter[n]/nOFpixels) for j in range(len(pixelCounter)): #Erstellt das Histogram plt.bar(j,pixelCounter[j]) plt.show() #Zeigt das Histogram an threshold= int(raw_input("Threshold eingeben bitte: ")) #Fordert input vom User an return threshold #Gibt den vom user gegebenen Wert zurück
Zeilen-Finder
Name im Code: ZeilenFindo. Damit die Zeichen in der Reihenfolge gefunden werden, in der sie auch vorkommen, und damit keine Zeichen übersehen werden, haben wir uns entschieden zuersteinmal die Zeilen (Bzw. Reihen) zu erkennen.
Die Methode testet jede zweite horizontale Reihe von Pixeln auf Helligkeitswerte unter einem bestimmten Grenzwert. Dafür ruft sie die Schwarz/Weiß-Tester Unten Links Methode auf. Ist ein Pixel dunkel genug, werden von unten nach oben die Reihen darüber getestet, bis eine ohne dunkle Pixel gefunden wird. Diese ist nun die obere Kante der Zeile. Danach wird von der ersten Zeile (in der ein dunkler Pixel gefunden wurde) aus die Zeilen darunter überprüft, bis eine Zeile ohne dunklen Pixel gefunden wird. Das ist nun die untere Kante der Zeile.
Der abgesteckte Bereich wird mit dem Zeichen-Finder durchsucht.
def ZeilenFindo(h,b,yMax,threshold,img): #h=Bildhoehe in Pixeln; b=BildBreite in Pixeln; yMax=OberGrenze fuer Suche; threshold=Grenzwert; img=BildMatrix; jmp=2 #Legt die Anzahl der Reihen fest, die uebersprungen werden (mehr=schneller=ungenauer) y=yMax #Setzt Obergrenze fest cx=1 #legt fest, auf welcher Breite die Suche beginnt zO=0 #Legt ZeilenObergrenze erst mal auf 0 fest zU=0 #Legt ZeilenUntergrenze erst mal auf 0 fest NextOben=True #Merkt sich, das die naechste zu findende Grenze die Obergrenze ist. while y<=h-2: #Diese Schleife durchsucht das Bild nach Zeilen if (swTester_OL(1,y,1,int(b*0.9),threshold,img) ==False) and (NextOben==True): #Die Schleife sucht nach einer Obergrenze, wenn in der aktuellen Reihe ein dunkler Pixel ist und die naechste zu findende Grenze die Obergrenze ist. cy=y-1 #Geht einen Pixel weiter hoch while swTester_OL(1,cy,1,b-1,threshold,img)==False: #Geht so lange hoch, bis in der Reihe kein dunkler Pixel mehr ist cy=cy-1 NextOben=False #Merkt sich, das die naechste zu findende Grenze NICHT die Obergrenze ist. zO=cy #Merkt sich die aktuelle Zeile als Obergrenze if (swTester_OL(1,y,1,int(b*0.9),threshold,img) ==False) and (NextOben==False): #Die Schleife sucht nach einer Untrgrenze, wenn in der aktuellen Reihe ein dunkler Pixel ist und die naechste zu findende Grenze NICHT die Obergrenze ist. cy=y+1 #Geht einen Pixel weiter runter while swTester_OL(1,cy,1,b-1,threshold,img)==False: #Geht so lange runter, bis in der Reihe kein dunkler Pixel mehr ist cy=cy+1 NextOben=True #Merkt sich, das die naechste zu findende Grenze die Obergrenze ist. zU=cy #Merkt sich die aktuelle Zeile als Untergrenze if zO>0 and zU>0: #Wenn beide Werte nicht mehr 0 sind (also eine Ober- und Untergrenze gefunden wurden) return zO,zU #Gefunde Werte werden zurueckgegeben y=y+jmp #Geht ein paar Zeilen weiter runter um dort weiter zu suchen return 0,0 #Das steht nur hier, weil das Programm sonst nicht mal starten will. Diese Zeile wird nie aufgerufen.
Zeichen-Finder
Name im Code: Skannomaton. Diese Methode durchsucht einen rechteckigen Bereich nach Zeichen. Als Kanten für das Rechteck dienen die Ober- und Unterkante der Zeile, die rechte Kante des zuvor gefundenen Zeichens (Bzw. der Anfang der Zeile) und die rechte Kante des Bildes. Das Ziel ist, einen Pixel zu treffen, der möglichst im oberen linken Bereich des Zeichens ist. Deshalb wird der Bereich von links nach rechts in „Scheiben“ durchsucht, welche leicht nach leicht nach rechts geneigt sind, ähnlich wie ein „/“. Wird ein dunkler Pixel gefunden, werden die Koordinaten zurückgegeben.
def Skannomaton(h,b,xMax,yMax,threshold,img): #h=Untergrenze fuer Suche; b=BildBreite in Pixeln (rechte Grenze fuer Suche); #xMax=LinkeGrenze fuer Suche; yMax=OberGrenze fuer Suche; threshold=Grenzwert; img=BildMatrix; y=yMax #Obergrenze x=xMax #LinkeGrenze while y < h: #Schleife laeuft bis der Algorithmus an der Unterkante vom Bereich ankommt. y=y+1 #Geht eins nach unten cy=y #Legt aktuelle Hoehe als Starthoehe der Suche fest cx=x #Legt aktuelle Breite als Startbreite der Suche fest while (cy>yMax) and (cx<b): #Schleife laeuft bis der Algorithmus an der oberen oder rechten Kante vom Bereich ankommt. if img[cy,cx]<threshold: #Wenn der aktuelle Pixel dunkel ist, werden die Koordinaten zurueckgegeben return cx,cy cx=cx+1 #Geht eins nach rechts cy=cy-2 #Geht zwei nach hoch while x < b-1: #Schleife laeuft bis der Algorithmus an der rechten Kante des Bildes ankommt. x=x+1 #Geht eins nach rechts cx=x #Legt aktuelle Breite als Startbreite der Suche fest cy=(h-1) #Legt Reihe ueber der Unterkante des Bereiches als Starthoehe der Suche fest. while (cy>yMax) and (cx<b): #Schleife laeuft bis der Algorithmus an der oberen oder rechten Kante vom Bereich ankommt. if img[cy,cx]<threshold: #Wenn der aktuelle Pixel dunkel ist, werden die Koordinaten zurueckgegeben return cx,cy cx=cx+1 #Geht eins nach rechts cy=cy-2 #Geht zwei nach hoch if (cx>=b-3) and (cy>=h-3): #Kommt das Programm zu nah an die untere rechte Ecke vom Bereich, wird das als Zeilen-/Seitenede gewertet return 0,0 #Es werden nur Nullen zurueckgegeben um das Ende zu Singnalisieren return 0,0 #Das steht nur hier, weil das Programm sonst nicht mal starten will. Diese Zeile wird nie aufgerufen.
Koordinaten-Anpasser Oberkante
Name im Code: Korrektoid. Diese Methode wurde zu dem Zweck geschrieben, den „Halbe Zeichen“-Fehler zu beheben. Sie nimmt den zuvor von Skannomaton gefundenen Punkt und bringt ihn auf die Höhe des höchsten Punktes des Buchstaben. Die Funktionsweise ähnelt der von Findomat_UR und Findomat_OL. Der Helligkeitswert des Pixels über dem Startpunkt wird getestet. Ist der Pixel dunkel, „bewegt“ sich Algorithmus nach oben, ist der Pixel hell, wird der Pixel auf der rechten Seit überprüft. Falls dieser Pixel dunkel ist, wird er zu neuen Startpunkt. Dies wird so lange wiederholt, bis beide Pixel hell sind, der Algorithmus also am lokalen Maximum des Zeichens angelangt ist. Der y-Wert des von Scannomaton übergeben Punktes wird nun durch den des lokalen Maximums ersetzt.
def Korrektoid(xS,yS,threshold,img): #xS=x-Koordinate Startpunkt; yS=y-Koordinate Startpunkt; treshold=Grenzwert; img=BildMatrix cx=xS cy=yS localMax=False #Legt Startkoordinaten fest und schaltet Abbruchbedingung aus while localMax==False and (cy>(yS-20)): #Solange das Maximum nicht gefunden wurde und das Programm sich nicht mehr #als 19 von der Starthoehe entfernt hat, wird nach dem Maximum gesucht. if img[(cy-1),cx]<threshold: cy=cy-1 #Wenn der Pixel ueber dem aktuellen dunkel ist, wird dieser der neue Ausgagngspixel else: if img[cy,(cx+1)]<threshold: cx=cx+1 #Wenn der Pixel rechts von dem aktuellen dunkel ist, wird dieser der neue Ausgagngspixel else: localMax=True #Gibt es keine dunklen Pixel direkt ueber oder direkt rechts vom aktuelle, ist das Maximum gefunden return cy #Hoehe des Maximums wird returnt
Rechte-Kante-Finder
Name im Code: Findomat_UR. Die Aufgabe dieser Methode ist es, die untere rechte Ecke des auszuschneidenden Bereiches zu finden. Dazu wird die vom Skannomaton erhaltene Koordinate solange nach unten und nach rechts verschoben, bis es möglich ist, von der neuen Koordinate eine vertikale Linie auf die ursprüngliche Höhe (y-Koordinate) und eine horizontale Linie auf die ursprüngliche Breite (x-Koordinate) zu zeichnen, ohne einen dunklen Pixel zu treffen. Um dies zu überprüfen, wird swTester_UR zur Hilfe genommen.
def Findomat_UR(x,y,yH,threshold,img): #x=x-Koordinate Startpunkt; y=y-Koordinate Startpunkt; yH=Von Korrektoid verbesserte y-Koordinate; #treshold=Grenzwert; img=BildMatrix cx=x+1 cy=y+1 clear=False #Geht schonmal eins nach unten rechts und setzt clear auf False while (clear==False): #Schelife laeuft so lange, wie clear False ist. if img[cy,cx]<threshold: cx=cx+1 cy=cy+1 #Wenn er Pixel dunkel ist gehts nach unten rechts else: #Wenn nicht, gehts hier weiter if swTester_UR(cx,cy,1,x,threshold,img)==False: cy=cy+1 #Wenn es NICHT moeglich ist, vom aktuellen Punkt aus eine horizontale Linie auf die Startbreite #zu ziehen, ohne einen dunklen Pixel zu treffen, geht der Algorithmus eins nach unten. if swTester_UR(cx,cy,0,yH,threshold,img)==False: cx=cx+1 #Wenn es NICHT moeglich ist, vom aktuellen Punkt aus eine vertikale Linie auf die Starthoehe #zu ziehen, ohne einen dunklen Pixel zu treffen, geht der Algorithmus eins nach rechts. if (swTester_UR(cx,cy,1,x,threshold,img)==True) and (swTester_UR(cx,cy,0,yH,threshold,img)==True): clear=True #Wenn es moeglich ist, vom aktuellen Punkt aus eine horizontale Linie auf die Startbreite #und eine vertikale Linie auf die Starthoehe zu ziehen, ohne einen dunklen Pixel zu treffen, #wird clear auf True gesetzt return(cx,cy) #Koordinaten für untere rechte Ecke werden zurueckgegeben.
Schwarz/Weiß-Tester Unten Rechts
Name im Code: swTester_UR. Die Methode bekommt einen Startpunkt, eine Zielkoordinate und eine Variable, die klar macht ob die Zielkoordinate ein x-Wert oder y-Wert ist. Dann versucht sie eine Line vom Start- zum Zielpunkt zu ziehen ohne einen dunklen Pixel zu treffen. Die „Linien“ können nur von unten nach oben und von rechts nach links gezogen weren. Ist die Aktion erfolgreich, wurde „True“ zurückgegeben, schlägt der versuch fehl, ist der Rückgabewert „False“.
def swTester_UR(x,y,w,zk,threshold,img): #x=Startbreite; y=Starthoehe; w=horizontal oder vertikal; zk=Zielkoordinate; h,b=img.shape #h ist die Hoehe des Bildes, b ist die Breite des Bildes cy=y cx=x #Setzt Startparameter if w==1: #Diese Schleife wird ausgefuehrt, wenn in x-Richtung getestet werden soll while (img[cy,cx]>=threshold): #Diese Schleife bewegt sich so lange nach links, bis entweder ein #dunkler Pixel gefunden wird (False) oder die Zielkoordinate erreicht wurde (True) if cx==zk: return True cx=cx-1 return False else: #Diese Schleife wird ausgefuehrt, wenn in y-Richtung getestet werden soll while (img[cy,cx]>=threshold): #Diese Schleife bewegt sich so lange nach oben, bis entweder ein #dunkler Pixel gefunden wird (False) oder die Zielkoordinate erreicht wurde (True) if cy==zk: return True cy=cy-1 return False
Koordinaten-Anpasser Unterkante
Name im Code: Korrektomat. Um korrekt zu funktionieren, benötigt Findomat_OL einen dunklen Pixel, welcher teil des Symbols ist. Diese Methode wurde geschrieben, um diesen Pixel zu finden. Die Startkoordinaten für die Suche sind die zuvor von Findomat_UR gefundenen Koordinaten der unteren rechten Ecke. Von dort aus bewegt sich die Methode nach links oben, bis sie auf einen dunklen Pixel trifft.
def Korrektomat(x,y,threshold,img): #x=x-Koordinate Startpunkt; y=y-Koordinate Startpunkt; treshold=Grenzwert; img=BildMatrix cx=x-1 cy=y-1 #Verschiebt die Koordinten des Punktes um eins nach links bzw oben while (img[cy,cx]>=threshold): cx=cx-1 cy=cy-1 #Verscheibt den Punkt solange nach oben links, bis der auf einem dunklen Pixel liegt return cx,cy #Gibt verbesserten Punkt zurueck
Linke-Kante-Finder
Name im Code: Findomat_OL. Diese Methode funktioniert im Prinzip genau so wie Findomat_UR. Der einzige Unterschied besteht darin, dass vom Startpunkt aus nach oben links (anstatt nach unten rechts). Um die Abbruchbedingung zu überprüfen, wird auch hier eine Hilfsmethode genutzt, in diesem Fall swTester_OL.
def Findomat_OL(x,y,threshold,img): #x=x-Koordinate Startpunkt; y=y-Koordinate Startpunkt; treshold=Grenzwert; img=BildMatrix cx=x-1 cy=y-1 clear=False #Geht schonmal eins nach oben links und setzt clear auf False while (clear==False): #Schleife laeuft so lange, wie clear False ist. if img[cy,cx]<threshold: cx=cx-1 cy=cy-1 #Wenn der Pixel dunkel ist gehts nach oben links else:#Wenn nicht, gehts hier weiter if swTester_OL(cx,cy,1,x,threshold,img)==False: cy=cy-1 #Wenn es NICHT moeglich ist, vom aktuellen Punkt aus eine horizontale Linie auf die Startbreite #zu ziehen, ohne einen dunklen Pixel zu treffen, geht der Algorithmus eins nach oben. if swTester_OL(cx,cy,0,y,threshold,img)==False: cx=cx-1 #Wenn es NICHT moeglich ist, vom aktuellen Punkt aus eine vertikale Linie auf die Starthoehe #zu ziehen, ohne einen dunklen Pixel zu treffen, geht der Algorithmus eins nach links. if (swTester_OL(cx,cy,1,x,threshold,img)==True) and (swTester_OL(cx,cy,0,y,threshold,img)==True): clear=True #Wenn es moeglich ist, vom aktuellen Punkt aus eine horizontale Linie auf die Startbreite #und eine vertikale Linie auf die Starthoehe zu ziehen, ohne einen dunklen Pixel zu treffen, #wird clear auf True gesetzt return(cx+1,cy) #Koordinaten für obere link Ecke werden zurueckgegeben. (+1 weil es dann ein bisschen schoener wird)
Schwarz/Weiß-Tester Oben Links
Name im Code: swTester_OL. Die Funktionsweise dieser Methode ist fast identisch mit der von swTester_UR. Der einzige Unterschied besteht darin, dass die der Algorithmus sich von oben nach unten Bzw. von links nach rechts über das Bild bewegt.
def swTester_OL(x,y,w,zk,threshold,img): #x=Startbreite; y=Starthoehe; w=horizontal oder vertikal; zk=Zielkoordinate; h,b=img.shape #h ist die Hoehe des Bildes, b ist die Breite des Bildes cy=y cx=x #Setzt Startparameter if w==1: #Diese Schleife wird ausgefuehrt, wenn in x-Richtung getestet werden soll while (img[cy,cx]>=threshold) and (cx<b): #Diese Schleife bewegt sich so lange nach rechts, bis entweder ein #dunkler Pixel gefunden wird (False) oder die Zielkoordinate erreicht wurde (True) if cx==zk: return True cx=cx+1 return False else: #Diese Schleife wird ausgefuehrt, wenn in y-Richtung getestet werden soll while (img[cy,cx]>=threshold) and (cy<h): #Diese Schleife bewegt sich so lange nach unten, bis entweder ein #dunkler Pixel gefunden wird (False) oder die Zielkoordinate erreicht wurde (True) if cy==zk: return True cy=cy+1 return False
Probleme und Herausvorderungen
Falsche Zeile
Anfangs trat ein Problem auf, bei dem das Programm in eine weiter unten liegende Zeile verrutscht ist und deswegen die restlichen Zeichen in der eigentlichen Zeile nicht mehr gefunden hat. Dieses Problem trat schon sehr früh auf und war einer der Hauptgründe dafür, den ZeilenFindo zu programmieren. Die Ursache des Bugs lag in der Funktionsweise des Skannomaton. Anfangs wurde als Unterkante des zu überprüfenden Bereichs die Unterkante des Bildes genommen. War nun der Abstand zwischen zwei Wörtern größer, als der Abstand zwischen den Zeilen, wurde also ein Zeichen aus der darunterliegend Zeile gefunden. War dieses nun fertig „eingerahmt“, wurde direkt dahinter mit der suche nach dem nächsten Symbol begonnen und so die darüber liegende Zeile „vergessen“.
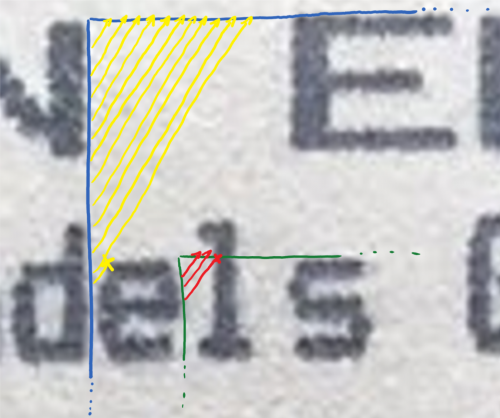
Blaue Linien: Erste Grenze für Skannomaton; Grüne Linien: Zweite Grenze für Skannomaton; Gelbe Pfeile: Erste Scan-Pfade; Rote Pfeile: Zweite Scan-Pfade; Kreuze: Punkt, an dem ein Symbol getroffen wird;
Halbe Zeichen
Bei Symbolen wie h, m, n, r ist es manchmal passiert, dass zuerst die linke Hälfte und dann nochmal das gesamte Zeichen erkannt wurde. Der Auslöser dafür war, dass der von Skannomaton gefundene Startpunkt manchmal nicht an der oberen linken Ecke des Symbols, sonder eher auf mittlerer höhe ist. Dadurch konnte Findomat_UR die untere rechte Ecke nicht mehr genau bestimmen. Das lag daran, dass die Ecke als gefunden gilt, wenn es möglich ist von der aktuellen Position eine horizontale Linie zur x-Koordinate des Startpunktes und eine vertikale Linie zur y-Koordinate des Startpunktes zu ziehen ohne den Buchstaben zu treffen. Die Methode Korrektoid umgeht dieses Problem, indem die von Skannomaton gelieferte y-Koordinate angehoben wird.
 Blauer Punkt: Startpunkt; Roter Punkt: Falsch erkannte Ecke; Grüner Punkt: richtige Ecke; Orange Linien: Überprüfte Pfade;
Blauer Punkt: Startpunkt; Roter Punkt: Falsch erkannte Ecke; Grüner Punkt: richtige Ecke; Orange Linien: Überprüfte Pfade;
Zusammenhängende Zeichen
Sind mehrere Zeichen zu eng zusammen gedruckt, kann es vorkommen, dass diese als zusammenhängendes Zeichen erkannt werden. So entsteht ein Ausschnitt mit mehreren Symbolen in einer Reihe. Wir habe uns darauf geeinigt, dass es leichter ist, dieses Problem mit Hilfe vom neuronalen Netzwerk im Nachhinein zu lösen. Extra neue Methoden in den Symbol-Finder zu integrieren würde vermutlich zu neuen Fehlern führen und wäre sehr viel aufwendiger und wahrscheinlich auch ungenauer.
Artefakte
Flecken, Schatten, Druckfehler, Stempel oder ähnliche Unreinheiten auf dem Papier sind teilweise dunkel genug um vom Programm als Symbol erkannt zu werden. Das kann dazu führen, dass Zeilen nicht richtig erkannt werden, in manchen Fällen hält das Programm dann zwei Zeilen für eine einzige. In solchen Fällen werden oft Buchstaben aus den beiden Zeilen nicht gefunden. Dieser Fall tritt aber nur bei relativ großen Artefakten ein, welche ziemlich selten sind, wenn man sich mit dem Foto etwas Mühe gibt. Kleinere Artefakte werden einfach als Symbole erkannt und an das neuronale Netzwerk übergeben, welches diese dann aussortieren soll. In diesem Teil des Programmes eine Lösung zu finden wäre zu aufwendig, vor allem da man mit einem neuronales Netzwerk ziemlich einfach erkennen kann, ob es sich um eine richtiges Symbol handelt oder nicht.
Machine Learning
Warum Machine Learning?
Menschen sind erstaunlich gut darin Bilder zu erkennen und Zusammenhänge zu finden. Computer im Gegensatz sehen ein Bild nur als Liste verschiedener Zahlen die für die RGB Werte des Pixels stehen. Dies macht es für Computer deutlich komplizierter Muster und Zusammenhänge auf Bildern zu erkennen. Deswegen muss man solche Probleme mit Machine Learning versuchen zu lösen.
„Maschinelles Lernen ist ein Oberbegriff für die „künstliche“ Generierung von Wissen aus Erfahrung: Ein künstliches System lernt aus Beispielen und kann diese nach Beendigung der Lernphase verallgemeinern. Das heißt, es werden nicht einfach die Beispiele auswendig gelernt, sondern es „erkennt“ Muster und Gesetzmäßigkeiten in den Lerndaten. So kann das System auch unbekannte Daten beurteilen oder aber am Lernen unbekannter Daten scheitern.“ - Wikipedia
Bei unserem Problem handelt es sich um ein Machine Learning Problem der Klassifizierung, das bedeutet, dass der Input bestimmten Klassen zuzuordnen.
Für alle Machine Learning Probleme ist es vor allem wichtig ein gutes Data-Set zu haben. Leider gibt es für die Erkennung gedruckter Buchstaben kein ausreichendes Data-Set, weshalb wir unserer Daten selbst generieren mussten. Dazu haben wir ein kleines Programm geschrieben, welches fünf verschieden Fonts kleine Bildchen erstellt und diese nach Buchstaben sortiert in Ordnern abspeichert.
Datengenerierung
Wir haben uns für die Fonts „Arial“, „Fake receipt“, „Merchant Copy“, „Moncao“ und „Times“ entschieden. Deren „.ttf“-Dateine haben wir anschließend wenn möglich direkt von unserem System in unseren Arbeitsordner rüberkopiert oder im Internet heruntergeladen.
font.py
import os from PIL import ImageFont from PIL import Image from PIL import ImageDraw import numpy as np ALPHABET_LOWER = "abcdefghijklmnopqrstuvwxyz" ALPHABET_UPPER = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" NUMBERS = "0123456789" SIGNS = "+-," slash= "/" star ="*" SIZE = (40, 50) def createFontImages(): fontArray = {} for root, dirs, files in os.walk("Fonts"): for font in files: FONT_NAME = font[:-4] font = ImageFont.truetype("Fonts/" + FONT_NAME + ".ttf", 25) for i in range(len(ALPHABET_LOWER)): if (FONT_NAME == 'fake receipt'): break img = Image.new("RGBA",SIZE,(255,255,255)) draw = ImageDraw.Draw(img) draw.text((0, 0),ALPHABET_LOWER[i],(0,0,0),font=font) draw = ImageDraw.Draw(img) fontArray["Images/" + ALPHABET_LOWER[i] + "/"+ FONT_NAME + ".jpg"] = img if not os.path.exists("Images/" + ALPHABET_LOWER[i]): os.mkdir("Images/" + ALPHABET_LOWER[i]) for i in range(len(ALPHABET_UPPER)): img = Image.new("RGBA",SIZE,(255,255,255)) draw = ImageDraw.Draw(img) draw.text((0, 0),ALPHABET_UPPER[i],(0,0,0),font=font) draw = ImageDraw.Draw(img) fontArray["Images/" + ALPHABET_UPPER[i] + "/"+ FONT_NAME + ".jpg"] = img if not os.path.exists("Images/" + ALPHABET_UPPER[i]): os.mkdir("Images/" + ALPHABET_UPPER[i]) for i in range(len(NUMBERS)): img = Image.new("RGBA",SIZE,(255,255,255)) draw = ImageDraw.Draw(img) draw.text((0, 0),NUMBERS[i],(0,0,0),font=font) draw = ImageDraw.Draw(img) fontArray["Images/" + NUMBERS[i] + "/"+ FONT_NAME + ".jpg"] = img if not os.path.exists("Images/" + NUMBERS[i]): os.mkdir("Images/" + NUMBERS[i]) for i in range(len(SIGNS)): img = Image.new("RGBA",SIZE,(255,255,255)) draw = ImageDraw.Draw(img) draw.text((0, 0),SIGNS[i],(0,0,0),font=font) draw = ImageDraw.Draw(img) fontArray["Images/" + SIGNS[i] + "/"+ FONT_NAME + ".jpg"] = img if not os.path.exists("Images/" + SIGNS[i]): os.mkdir("Images/" + SIGNS[i]) img = Image.new("RGBA",SIZE,(255,255,255)) draw = ImageDraw.Draw(img) draw.text((0, 0),slash,(0,0,0),font=font) draw = ImageDraw.Draw(img) fontArray["Images/" + "slash" + "/"+ FONT_NAME + ".jpg"] = img if not os.path.exists("Images/slash"): os.mkdir("Images/slash") img = Image.new("RGBA",SIZE,(255,255,255)) draw = ImageDraw.Draw(img) draw.text((0, 0),star,(0,0,0),font=font) draw = ImageDraw.Draw(img) fontArray["Images/" + "star" + "/"+ FONT_NAME + ".jpg"] = img if not os.path.exists("Images/star"): os.mkdir("Images/star") return fontArray
font_main.py
from PIL import Image import ImgUtls as iu import font import argparse import sys import numpy as np import os def main(): allImages = np.array([]) imagesNames = np.array([]) fonts = font.createFontImages() fontKeys = fonts.keys() i = 0 bar_len = 60 for key in fontKeys: percent = round(i/3.08,1) a = int(percent*.6) bar = '=' * a + '>'+ '-' * (bar_len - a-1) sys.stdout.write('[%s] %s%s \r' % (bar, percent, '%')) sys.stdout.flush() i+=1 fonts[key] = iu.crop(fonts[key]) fonts[key].save(key) if __name__ == "__main__": main()
Die relevanten Dateien für die Datengenerierung lauten „font.py“ und „font_main.py“. „font.py“ liest die „.ttf“ Dateien ein und erstellt mittels der Python Image Library unterschiedliche Symbole bestehend aus Buchstaben, Ziffern und Zeichen. Diese werden als Array mit dem Namen „fontArray“ in font_main.py übergeben um auf die richtige Größe geschnitten zu werden. Gespeichert werden sie im selben Arbeitsordner unter „Images/“, in einem weiteren Ordner betitlet mit dem Zeichen das gespeichert wird.
Die „ImgUtls.py“ Library beinhaltet 3 Funktionen die sich alle auf das bearbeiten von Bildern konzentrieren.
getSchwerpunkt(img)
# Returns coordinates of contrast richest point def getSchwerpunkt(img): img_arr = np.array(img) rows = len(img_arr) cols = len(img_arr[0]) #im_arr = np.array(img) img = img.crop((1,1,rows,cols)) # Sammle nicht-weisse Pixel Koordinaten horizontal nonWhitePixelCoordsX = [] for row in range(rows): for col in range(cols): r, g, b = img_arr[row][col][0], img_arr[row][col][1], img_arr[row][col][2] if (r, g, b) != (255, 255, 255): nonWhitePixelCoordsX.append(row) # Sammle nicht-weisse Pixel Koordinaten vertikal nonWhitePixelCoordsY = [] for col in range(cols): for row in range(rows): r, g, b = img_arr[row][col][0], img_arr[row][col][1], img_arr[row][col][2] if (r, g, b) != (255, 255, 255): nonWhitePixelCoordsY.append(col) # Berechne schwarzeste x koordinate x = round(sum(nonWhitePixelCoordsX) / float(len(nonWhitePixelCoordsX))) # Berechne schwarzeste y koordinate y = round(sum(nonWhitePixelCoordsY) / float(len(nonWhitePixelCoordsY))) return (x, y)
Die Funktion „getSchwerpunkt“ iteriert vertikal wie auch horizontal durch dass gesamte Bild und merkt sich jede nicht-weiße Koordinate. Anschließend wird die durchschnittlich „dunkeleste“ Koordinate zurückgegeben, was bei einem Bild mit weißen Hintergrund und einem schwarzen Buchstaben ungefähr der mittlerste Punkt des Buchstaben ist.
crop(img)
# Returns the centered letter as an image def crop(img): sp = getSchwerpunkt(img) img_arr = np.array(img) rows = len(img_arr) cols = len(img_arr[0]) # Probiere von SP nach links vertikale Linien zu ziehen. Wenn diese Linie nicht auf Schwarz trifft, speicher koordinaten ab. # Vertikale Linie von SP nach links pos = [0, int(sp[1])] while(pos[0] != (len(img_arr) - 1)): if (img_arr[pos[0]][pos[1]][0], img_arr[pos[0]][pos[1]][1], img_arr[pos[0]][pos[1]][2]) != (255, 255, 255): pos[0] = 0 pos[1] -= 1 continue pos[0] += 1 y_cord_left = pos[1] # Vertikale Linie von SP nach rechts pos = [0, int(sp[1])] while(pos[0] != (len(img_arr) - 1)): if (img_arr[pos[0]][pos[1]][0], img_arr[pos[0]][pos[1]][1], img_arr[pos[0]][pos[1]][2]) != (255, 255, 255): pos[0] = 0 pos[1] += 1 continue pos[0] += 1 y_cord_right = pos[1] # Horizontale Linie von SP nach oben pos = [int(sp[0]), 0] while(pos[1] != (len(img_arr[0]) - 1)): if (img_arr[pos[0]][pos[1]][0], img_arr[pos[0]][pos[1]][1], img_arr[pos[0]][pos[1]][2]) != (255, 255, 255): pos[0] -= 1 pos[1] = 0 pos[1] += 1 x_cord_top = pos[0] # Horizontale Linie von SP nach unten pos = [int(sp[0]), 0] while(pos[1] != (len(img_arr[0]) - 1)): if (img_arr[pos[0]][pos[1]][0], img_arr[pos[0]][pos[1]][1], img_arr[pos[0]][pos[1]][2]) != (255, 255, 255): pos[0] += 1 pos[1] = 0 pos[1] += 1 x_cord_bottom = pos[0] # Return cropped image return img.crop((y_cord_left+1, x_cord_top+1, y_cord_right, x_cord_bottom ))
Die crop() Funktion soll einen Buchstaben positioniert irgendwo auf einem weißen Hintergrund ausschneiden und zurückgeben. Dafür bedient sie sich der getSchwerpunkt() Funktion. Nachdem der Schwerpunkt des Bildes festgestellt wurde, iteriert die Funktion Vertikal wie auch Horizontal von dem Schwerpunkt auf der Sucher nach einer Linie ununterbrochener weißer Pixel. Nachdem es diese gefunden hat speichert es sich die entsprechenden Eck-Koordinaten ab und gibt das mittels der crop Funktion der Python Image Library beschnittene Bild zurück.
addNoise(img)
# For each pixel (excluding pixels associated to the letter) in a given image a # random value is added/subtracted from the current RGB value creating random noise. def addNoise(img): img_arr = np.array(img) rows = len(img_arr) cols = len(img_arr[0]) img_arr_cp = img_arr for row in range(rows): for col in range(cols): if (img_arr[row][col][0], img_arr[row][col][1], img_arr[row][col][2]) >= (150, 150, 150): pass else: new_value = img_arr[row][col][0] new_value += rnd.randint(-100, 20) if new_value > 255: new_value = 255 elif new_value < 0: new_value = 0 for value in range(3): img_arr[row][col][value] = new_value return img Image.fromarray(img_arr)
In „addNoise(img)“ wird auf jeden Pixel ein zufälliger Wert zwischen -100 und 20 aufaddiert. Dadurch werden zufällig unreinheiten, auch „Noise“ genannt, in das Bild eingefügt. Dies simuliert unreinheiten bei der Aufnahme eines echten Bildes und verhindert das unser neurales Netzwerk ausschließlich auf „perfekte“ Bilder trainiert.
functions.py
Die Datei functions.py ist eine Zusammenstellung aus unterschiedlichen kleineren Funktionen die an verschiedenen Stellen im Programm benutzt werden. Unter anderem, sind hier die Funktionen zum Erstellen des characterArrays gespeichert. Das characterArray soll die vom Kassenbon erkannten Zeichen abspeichern, in er selben relativen Position wie auf dem Kassenbon.
def getCharArray(model): X = 0 Y = 0 for path, dirs, files in os.walk("SymbolGen"): for filename in files: filename = filename[:len(filename) - 4] row, X_pos, Y_pos = filename.split("_") try: if int(X_pos) > X: X = int(X_pos) if int(row) > Y: Y = int(row) except: print("Error: Filename of found letters not a valid integer") quit(0) arr = [["__" for y in range(Y)] for x in range(X)] print (X_pos, row) return getLetter(arr, model)
Dafür muss erstmal ein Array initialisiert werden in das all die gefundenen Zeichen aufgenommen werden können. Alle bisher gefundenen Zeichen wurden in einem Ordner gespeichert und haben eine Bezeichnung der Form „REIHE_XWERT_YWERT.png“. getCharArray iteriert durch diese Dateinamen und initialisiert das characterArray mit dem höchsten Reihen-Wert und dem höchsten X-Wert den es finden kann.
Aufbau des Neuronalen Netzwerks
Neuronale Netzwerke sind eine bestimmte Art von Machine Learning. Die Grundidee kommt aus dem Vergleich mit dem Gehirn, woher auch der Name „Neuronal“ kommt. Die Idee ist dass man ganz viele Verbundene künstliche „Neuronen“ zusammen die optimale Lösung finden. Die künstlichen Neuronen sind natürlich auch nur programmiert. Unser Neuronales Netzwerk basiert auf den Modulen von der Keras Library. Das Prinzip von Keras ist, dass man sein Neuronales Netzwerk aus Layers aufbaut.
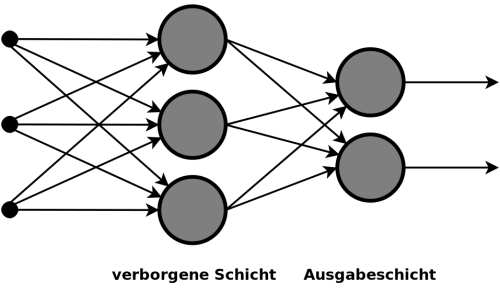 So kann man sehr vereinfacht ein Neuronales Netzwerk darstellen.
So kann man sehr vereinfacht ein Neuronales Netzwerk darstellen.
Um ein Neuronales Netzwerk trainieren zu können, braucht man zu aller erst ein Data-Set. Da wir kein geeignetes Data-Set bekommen haben, haben wir Generatoren benutzt, welche verschiedene Bilder von den oben beschriebenen Font Bildern erstellt und diese auch noch etwas verändert, indem es etwas Zoom hinzufügt und sie leicht dreht. Hier ein Beispiel um unseren Trainingsgenerator zu erstellen.
train_datagen = ImageDataGenerator( rescale=1./255, rotation_range = 10, shear_range=0.8, zoom_range=0.8, fill_mode='nearest', data_format='channels_first' ) train_generator = train_datagen.flow_from_directory( 'Images', target_size=(30, 20), color_mode = "grayscale", batch_size=32, class_mode='categorical')
Der erste Schritt den ein Neuronales Netzwerk durchführen muss wenn es Bilder von Buchstaben verarbeiten will, ist diese Bilder zu verkleinern und vereinfachen. Dazu haben wir die Convolutional Layer hinzugefügt. Diese ist ein Filter den man auf das Bild legen kann womit man zum Beispiel Kanten sehr gut hervorheben kann.
Danach haben wir eine Aktivierungsfunktion festgelegt. Ein Neuron braucht eine Aktivierungsfunktion, damit festgelegt ist, wann es aktiviert wird und das Signal somit weiter gibt. Unsere Aktivierungsfunktion heißt ReLU. Die nächste Layer ist eine MaxPooling Layer. Diese hat die Funktion aneinander liegende Pixel zusammen zufassen, sodass das Bild deutlich komprimiert wird.
Die letzte Layer der Bild Bearbeitung ist die Flatten Layer. In dieser wird das Bild nochmal zusätzlich vereinfacht.
Danach kommen die Dense Layers. Diese bilden dann das eigentliche Neuronale Netzwerk. Eine Dense Layer besteht aus einer im Methodenkopf anzugebenen Anzahl an „Neuronen“ wobei alle untereinander vernetzt sind. Diese Vernetzung wird Unterschiedlich gewichtet, wobei diese Gewichtung dann gelernt wird.
Als letztes muss man noch fit benutzen um das Model zu trainieren.
vision_model.add(Conv2D(nkerns[0], (8, 8) ,activation=None, padding='valid',data_format = "channels_first", input_shape=(1, 30,20))) vision_model.add(keras.layers.advanced_activations.LeakyReLU(alpha=alpha)) vision_model.add(MaxPooling2D((2, 2))) vision_model.add(Flatten()) vision_model.add(Dense(hidden,activation=None,kernel_regularizer=keras.regularizers.l1_l2(reg_l1,reg_l2)))#,kernel_regularizer=keras.regularizers.l1_l2(reg_l1,reg_l2))) vision_model.add(keras.layers.advanced_activations.LeakyReLU(alpha=alpha)) vision_model.add(Dense(67,activation='softmax', name='main_output')) vision_model.fit_generator(train_generator, steps_per_epoch= 1000, epochs=n_epochs, validation_data=validation_generator, validation_steps=40)
Dies ist ein Beispiel für ein sehr einfaches Neuronales Netzwerk, welche die Beschriebenen Layers enthält. Wir haben mit sehr vielen Verschieden Kombinationen dieser Layers getestet sind aber noch nicht zu einem befriedigendem Ergebnis gekommen, weil wir die Modelle overfittet haben. Das bedeutet, dass man das Modell zu genau trainiert und es dadurch nicht verallgemeinern kann.
Predictions und Verarbeitung
Ein weiteres Problem was wir hatten war die Modelle zu Bewerten. Dazu haben wir das Modell einfach über unsere Testbilder laufen lassen und geguckt wie viele es richtig bewertet. Dabei ging es aber erst mal darum einen Eindruck über die ungefähre Genauigkeit zu bekommen. Den richtigen Test haben wir dann mit Bildern von ausgeschnittenen Text gemacht welche das Programm dann als String ausgeben sollte. Dabei sind jedoch die meisten Modelle gescheitert und man konnte oft nicht wiedererkennen was der eigentliche Text sein sollte. Ein weiteres Problem was wir hatten war die Leerzeichen richtig zu setzen. Dies haben wir dann dadurch gelöst, dass wir den Anfangs und Endpixel in Y- Richtung uns merken und dann bei einem zu großen Unterschied ein Leerzeichen in den Text einfügen. Dieses Verfahren ist aber sehr anfällig, weil man einen festen Wert braucht der ungefähr die Größe eines Leerzeichens darstellt.
Unsere Gruppe bestand aus Jan, Tessa, Lucas, Lea und Benni