Benutzer-Werkzeuge
Seitenleiste
Dies ist eine alte Version des Dokuments!
Inhaltsverzeichnis
BEMERKUNGEN ZUR VERBESSERUNG
Ich würde mir vor der Darstellung der einzelnen Teile des Programms noch einen Abschnitt wünschen, der insgesamt erklärt, was jetzt kommt und wie es zusammengehört, auch gerne mit einem Bildchen. Man sollte immer an Leser denken, die wenig davon wissen.
Im Abschnitt zur STFT fände ich es gut, die Problemstellung aus dem Quest noch weiter auszuarbeiten, um Lesern, die keine Ahnung davon haben, einen Begriff von der Schwierigkeit bekommen, Eigenschaften von Musikstücken zu finden, die relativ robust sind gegen Störungen. (Ein Text, der die Lösungen eines technischen oder wissenschaftliches Problem beschreibt, ist dann besonders lesbar, wenn nicht nur erkennbar ist, dass, sondern auch warum dieses oder jenes zur Lösung beiträgt. Hier wäre etwa STFT (zusammen mit dem nachgelagerten Fingerprinting, das ihr gut dokumentiert habt) als Antwort auf das geschilderte Problem erkennbar. Es ist auch schön, wenn der Leser selbst nachdenkt, um welche Merkmale es gehen könnte, bevor er die Antwort bekommt. Bzw. die Leserin.)
Die Planung und der Verlauf lässt sich gut am Logbuch studieren. Ich wünsche mir aber, wieder für einen Leser, der sich informieren will, eine – kurze – Erzählung des Verlaufs des Projekts. (Auch: wo es hing.)
Und es fehlt noch ein (kurzes) Fazit, z.B. auch eine Skizze, wie es weiter gehen könnte.
Musik-Erkennung
Gruppe
- Fritz
- Benny
- Nico
Inventar
- Python 2.7
- Pyaudio
- Kaffee
- Sci-Kit Learn
- mehr Kaffee
Motivation
Ähnlich Shazam, Soundhound, etc. Musik, die man z.B. im Radio hört, zu erkennen und den Titel auszugeben.
Quellen und Links
Quest
Ziel wird es nicht sein, wie die genannten Apps fast alle Musikstücke zu erkennen. Das würde doch enormen Speicheraufwand bedeuten und liegt nicht im Fokus des Arbeitens. Schön wäre es jedoch möglichst viele Lieder erkennen zu können. Stattdessen wird besonders darauf Wert gelegt, die Schallsignale auf ihre Besonderheiten zu analysieren und damit eindeutig zu einem Lied zuordnen zu können. Dabei kann auch beispielsweise Augenmerk auf die Klangbilder einzelner Instrumente oder Teile des Instruments (z.B. Snare beim Schlagzeug) gelegt werden.
Bonus-Quests
Mehr Lieder. Zusammenarbeit mit der Dirigenten-Gruppe: Spannend wäre es hier vor allem, wenn man die Ausgangssignale der Dirigenten-Gruppe analysieren würde und somit den Erfolg der Ton-Ausgabe überprüfen könnte. Die Kette würde also so aussehen: Der Dirigent macht Bewegungen. Aus diesen wird ein Lied abgeleitet. Dieses wird aufgenommen und dann analysiert und der Titel angegeben. Möglicherweise könnte man so aus den Bewegungen des Dirigenten den Namen des Titels ausgeben.
wichtige Bestandteile des Programms
Im Folgenden werden die Basis-Funktionen des Programms erläutert. Diese bestehen aus: 1. der Umwandlung einer Audiodatei in eine Zahlenfolge, mit der dann weiter gearbeitet/ gerechnet werden kann; 2. der weiteren Umwandlung dieser Daten mittels Short-Time-Fourier-Transformation. Dieses Verfahren wird benötigt, um aus dem Song den Frequenzbereich zeitabhängig zu bestimmen; 3. dient der Veranschaulichung und kann sehr hilfreich für das Verständnis der Vorgänge sein: das Erstellen eines Spektrogramms, darüber hinaus wird das fingerprinting (wird anschließend vorgestellt) in unserem Programm mit dem Spektrogramm umgesetzt; 4. Audio-fingerprinting, d.h. markante/charakteristische Punkte aus dem fourier-transformierten Datensatz erkennen/ filtern, wird hier mit dem Bild des Spektrogramms erstellt; 5. Erstellen einer Datenbank, Sammeln der Daten für den späteren Vergleich; 6. der Vergleich, letztendlich der entscheidene Schritt, um zu testen, ob ein aktuell abgespieltes Lied mit einem aus der Datenbank übereinstimmt. Hier ist die Vergleichsfunktion aufgetragen, vorher durchläuft das abgespielte Lied erstmal die ersten 4 Schritte, dann werden die beiden Datensätze mit der genannten Funktion verglichen
Einlesen von Audio-Dateien
"""Liest ein wav-File in ein numpy-Array""" def wavread(filename): global ANZAHL global RATE global DAUER RATE,y = wavfile.read(filename) # in y ist die Anzahl der Frames und bei mehreren Channels die Anzahl der Channels gespeichert ANZAHL = y.shape[0] if len(y.shape)==2: y = y.astype(float) yKonf = y.sum(axis=1) / 2 else: yKonf = y DAUER=ANZAHL/RATE return np.array(yKonf,dtype=np.float)/2**15 """ empfange Audiosignale und schreibe sie in ein Numpy-Array """ def getAudio(): # Audioeingang initialisieren p = pyaudio.PyAudio() stream = p.open(format=pyaudio.paInt16, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNKSIZE) # Daten schreiben frames = [] # Liste von Chunks(Blöcken) for i in range(0, int(RATE / CHUNKSIZE*DAUER)): data = stream.read(CHUNKSIZE) frames.append(np.fromstring(data, dtype=np.int16)) # evtl nur normal int? Datengröße müssen wir wohl später abschätzen was sinnvoll ist # Liste der numpy-arrays in 1D-array konvertieren numpydata = np.hstack(frames) # Stream schließen stream.stop_stream() stream.close() p.terminate return numpydata
Datenverarbeitung mittels Short-Time Fourier Transform
Die Short-Time Fourier Transformation ist eine Art der Fourier Transformation, um die zeitliche Änderung des Frequenzspektrums eines zum Beispiel Audiosignals darzustellen. Das eingelesene Audiosignal wird hier in einen Datensatz umgewandelt, welcher später als Spektrogramm geplottet werden kann.
""" Short-Time Fourier Transformation """ #bisherige Funktion def stft(x, fs, framesz, hop): x=np.concatenate((x,np.zeros(1))) halfwindow = int(np.round(framesz*fs/2)) framesamp=2*halfwindow+1 hopsamp = int(np.round(hop*fs)) w = scipy.hamming(framesamp) X = scipy.array([scipy.fft(w*x[i-halfwindow:i+halfwindow+1]) for i in range(halfwindow, len(x)-halfwindow, hopsamp)]) return X
Die STFT ist immer noch der größte Zeitfresser bei der Analyse von Audiosignalen und der Erstellung von Fingerprints. In einer früheren Version benötigte des Programm noch bis zu 10 min für die Analyse eines einzelnen 3 min Stückes. Dank einigen Optimierungen konnten wir dies verkürzen. Eine neue noch schnellere Variante muss noch implementiert werden.
"""
schnellere Funktion, hanning statt hamming, framesamp geändert
def stft(x, fs, framesz, hop):
x=np.concatenate((x,np.zeros(1)))
halfwindow = int(np.round(framesz*fs/2))
framesamp=2*halfwindow
hopsamp = int(np.round(hop*fs))
w = scipy.hanning(framesamp)
X = scipy.array([scipy.fft(w*x[i-halfwindow:i+halfwindow]) for i in range(halfwindow, len(x)-halfwindow, hopsamp)])
print X.shape
return X[:,0:800]
"""
Spektrogramm erstellen
Spektrogramme dienen dem Zweck ein Frequenzspektrum bildlich darzustellen. Bei der Arbeit mit Audiosignalen kann an einem Spektrogramm die jeweilige Intensität der verschiedenen Frequenzen abgelesen werden.
"""Spektrogramm erstellen""" #""" def spect(numpydata): fensterdauer=0.1 fensterueberlappung=0.025 # jeweils in Sekunden A=stft(numpydata,RATE,fensterdauer,fensterueberlappung) A = A[:,0:800] eps=1e-8 # Offset, um logarithmieren zu koennen r,s=A.shape return A #"""
Audio-Fingerprinting
Nachdem ein Spektrogramm erstellt wurde, besteht das nächste Ziel daraus, einen sogenannten „Audio-Fingerprint“ zu erstellen. Dazu wird unser Spektrogramm zunächst als einfaches Bild eingelesen.
"""Spektrogramm als Bild einlesen""" def im_conversion(data): r,s = data.shape eps = 1e-8 data = np.log10(np.absolute(data[:,:s/2]+eps)) im = color.rgb2gray(data) return im
Ein „Audio-Fingerprint“ ist, ähnlich wie der Fingerabdruck eines Menschen, eine Möglichkeit einer Audiodatei eine eindeutige Identität zuzuordnen. Zur schlussendlichen Erkennung eines Musikstückes ist daher eine Möglichkeit dieses anhand bestimmter Merkmale zu identifizieren von großer Bedeutung.
Zunächst werden im Spektrogramm lokale Maxima gesucht, Punkte, welche für die weitere Bearbeitung interessant scheinen.
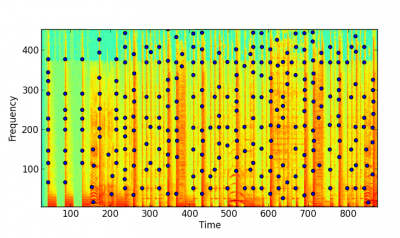
Im Code wurde dies wie folgt realisiert. Die Funktion „peak_local_max()“ wurde dem Paket „skimage“ entnommen und findet lokale Maxima in Bildern.
""" finde lokale Maxima im Bild """ def fpeaks(im): peaks = peak_local_max(im, min_distance=9) # min_distance bestimmt Anzahl der Peaks peaks = zip(peaks[:,0], peaks[:,1]) #print len(peaks) return peaks
Jedoch ist es auf Grund der Fülle von Liedern nicht gerade unwahrscheinlich, dass zwei oder mehr Lieder gleiche lokale Maxima in ihren Spektrogrammen aufweisen. Mittels einer sogenannten „Hash-Funktion“ wird dieses Problem gekonnt umgangen. Eine Hash-Funktion nimmt einen Integer-Wert als Input und gibt einen anderen Integer-Wert als Output zurück.
So z.B. können aus den Frequenzen unserer lokalen Maxima und deren zeitlicher Abstand zueinander als Input ein eindeutiger Audio-Fingerprint erstellt werden.
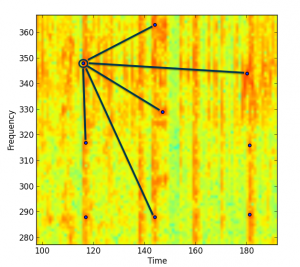
""" erstelle fingerprint hashes """ def fingerprint(peaks): # peaks tupel sind schon bzgl. zeit sortiert fingerprint_list = [] for i in range(len(peaks)): for j in range(1, PAIR_VAL): if (i+j < len(peaks)): freq1 = peaks[i][1] # nimmt 2. wert, heißt die frequenz, des zeit/freq tupels (stelle 1) freq2 = peaks[i+j][1] # zweiter peak time1 = peaks[i][0] # nimmt 1. wert, heißt die zeit, des zeit/freq tupels (stelle 0) time2 = peaks[i+j][0] # zeit des zweiten peaks delta_time = time2 - time1 # zeitliche differenz zwischen den peaks if (delta_time >= MIN_HASH_TIME_DELTA and delta_time <= MAX_HASH_TIME_DELTA): h = hashlib.sha1("%s|%s|%s" % (str(freq1), str(freq2), str(delta_time))) fingerprint_list.append((h.hexdigest()[0:FINGERPRINT_CUT], time1)) return fingerprint_list
Die Möglichkeiten diese zu erstellen sind zahlreich. Es herrscht jedoch immer ein gewisser Drahtseilakt zwischen mehr lokalen Maxima , was in leichter zu unterscheidenen Fingerabdrücken resultiert und weniger lokalen Maxima, welche allerdings eine stärkere Unterdrückung von Umgebungsgeräuschen zur Folge haben, sowie höhere Ausführungsgeschwindigkeit.
Eine Datenbank erstellen (lite)
Unser erster Gedanke war es eine kleine Datenbank zu erstellen, welche Informationen zu Song, Album, Künstler, Genre und vor allem den Fingerprint Hash beinhaltet. Diese sollte auf Basis von SQL Lite entstehen. Da wir uns zum Ende des Semesters eingestehen mussten, dass eine Datenbank von mehreren 100 Songs eher unnötig ist, vor allem andere Teile des Programms bedürfen zuerst einer Optimierung, werden die aktuell eingelesenen Titelnamen der Fingerprints mittels Pickle in einer Textdatei gespeichert. Die einzelnen Fingerprints jedes einzelnen Songs befinden sich in einer jeweils eigenen Textdatei. Diese können dann später beim Vergleichen von Audiosignalen nacheinander aufgerufen werden. Momentan besteht unsere Datenbank.txt Datei nur aus den Songs des Albums „AM“ von den Arctic Monkeys:
01 Do I Wanna Know 02 R U Mine _ 03 One For The Road 04 Arabella 05 I Want It All 06 No 1 Party Anthem 07 Mad Sounds 08 Fireside 09 Why`d You Only Call Me When You`re High 10 Snap Out of It 11 Knee Socks 12 I Wanna Be Yours
Ein Fingerprint eines einzelnen Songs sieht in etwa so aus (nur die ersten paar Zeilen, da die komplette Datei den Rahmen dieses Wikis sprengen würde, etwa 6MB an Text):
(lp1 (S'b06f456e4ed24d78d8be' cnumpy.core.multiarray scalar p2 (cnumpy dtype p3 (S'i8' I0 I1 tRp4 (I3 S'<' NNNI-1 I-1 I0 tbS'5\x00\x00\x00\x00\x00\x00\x00' tRp5 tp6 ...
Der Vergleich zweier Audiodateien
"""Vergleich mit Fingerprint aus Datenbank""" def comp_fingprt(fpaktuell): with open("Datenbank.txt","r") as db: # Datenbank ist ein Text-File mit allen Dateinamen, mit denen verglichen werden soll for fname in db: fname = fname.rstrip("\n") # mit der append-Funktion wird beim einlesen ein newline an den Dateinamen angehängt with open("%s.txt" % fname,"r") as f: # das newline Zeichen muss hier gestrichen werden fpdatenbank = pickle.load(f) """ check if fingprt_aktuell is in fingprt_datenbank """ matches = [] differences = [] for hash_a, time_a in fpaktuell: for hash_d, time_d in fpdatenbank: if hash_a == hash_d: matches.append((hash_a,time_a,time_d)) tdiff = time_d - time_a differences.append(tdiff) variance = np.var(differences) if len(matches) > 250 and variance < 10000000: # durch verändern der Werte wird Toleranz bestimmt print fname # len(matches) = Anz. der Übereinstimmungen, Varianz = Index für Zeitfehler